通用爬虫
爬虫的基本用法
Python 中原生的一款基于网络请求的模块,功能强大,简单便捷,效率极高。
>_: pip install requests
基本使用
- 指定URL
- UA伪装
- 发起请求 ——
requests.get() 或 requests.post()
- 获取响应数据 ——
.json()或.text
- 持久化存储 ——
f.write() 或 json.dump()
| import requests
def main():
# 1. 指定url
url = "https://www.sou.com"
# 2. UA伪装
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.44"}
# 3. 发起请求
response = requests.get(url=url, headers=header)
# 4. 获取响应数据
page_text = response.text
# 5. 持久化存储
with open("sogou.html", "w", "utf-8") as f:
f.wirte(page_text)
print("END")
if __naim__ == '__main__':
main()
|
这种就是最基本的模拟浏览器进行爬取。
通过requests就可以进行网络请求,从返回对象中得到数据。
url的获取方式主要通过自己查找分析
如果只是普通的浏览网页,一般使用的是get方式
如果携带参数,需要观察url中 ? 后面的字段。
携带参数
http协议中的请求方式分为get、post、put、patch、head、delete。
最常用的请求为 get() 和 post(),这两种请求方式都可以携带参数。
在浏览器中分析的时候可以观察 ? 后面的字段,有的是query,有的是q,可以通过浏览器中抓包工具进行分析
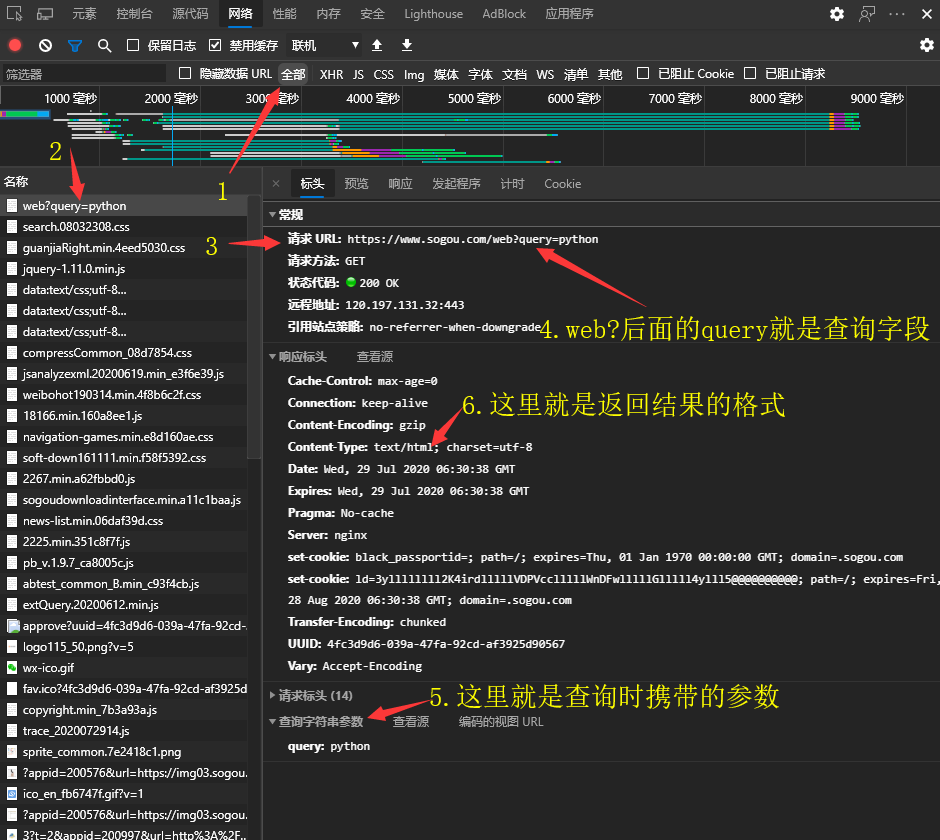
- 由此就可以确定
? 前面是我们要的url: https://www.sogou.com/web?;url中的问号?可写可不写
- 接着可以确定查询字段是
query,用个字典包装起来:param = {'query': 'python'}
- 同时在请求url下面可以看到请求方式是get,所以可以使用get方法进行请求:
res = requests.get(url, param, headers=header)
- 观察响应标头的
Content-Type发现,返回格式为text,则调用res.text获得返回内容:res_text = res.text
- 将返回的内容存储起来。搞定。
完整代码
| import requests
header = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.44"}
def main():
# 1. 指定url
url = "https://www.sogou.com/web?"
# 2. 获取查询内容
q = input('Enter the contend you want to search: ')
# 3. 设置好传输参数
param = {'query': q}
# 4. 发送请求
res = requests.get(url=url, params=param, headers=header)
# 5. 获取返回内容
res_text = res.text
# 6. 写入文件
with open('./sogou.html', 'w', encoding='utf-8') as f:
f.write(res_text)
if __name__ == '__main__':
main()
--------------------------------------------------
# Output:
Enter the contend you want to search: Python
|
| # sogou.html
<!DOCTYPE html>
<html data-vtype="default">
<head>
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta http-equiv="x-dns-prefetch-control" content="on">
<meta charset="utf-8">
<meta name="referrer" content="always">
......
</script><!-- BottomViewEnd opt -->
<script crossorigin="anonymous" src="//dlweb.sogoucdn.com/hhytrace/trace_2020072915.js" async></script>
</body><!-- bodyViewEnd -->
</html><!-- 1596006531756 -->
<!--STATUS total 14 time 1596006531756 page 0 maxEnd 1000 totalItems 8955-->
<!--real_pageno:1-->
<!--nodeserverinfo:rsync.doc04.web.1.gd.ted-->
<!--searchhubserverinfo:doc09.web.1.gd.ted:5555-->
<!--zly-->
|
requests模块中的get()、post()、put()等请求方法其实都是调用了request()方法。
request(method, url, **kwargs)
get(url, params=None, **kwargs)
post(url, data=None, json=None, **kwargs)
这里注意区分,get的参数是params,post的参数的data
抓取动态内容
网页中有些数据不是静态的,而是动态获取,通过Ajax局部刷新。
例如百度翻译
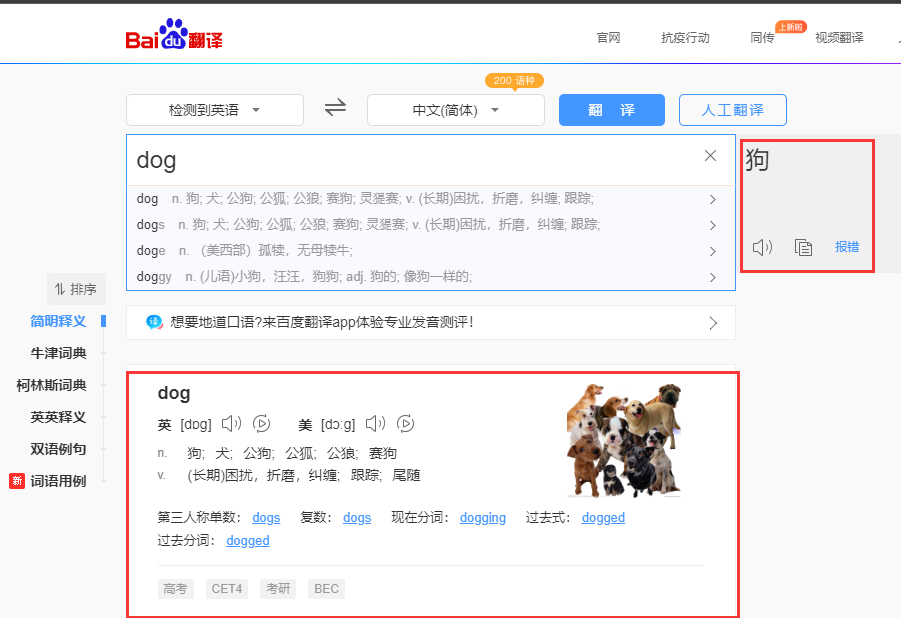
红框中的内容会根据输入框中内容的变化而变化,这就是**动态获取**
当内容改变的时候,返回来的结果只会改变页面中红框的部分,这就是**局部刷新**
这种数据直接抓取页面是无效的,所以我们要通过浏览器抓包工具进行观察
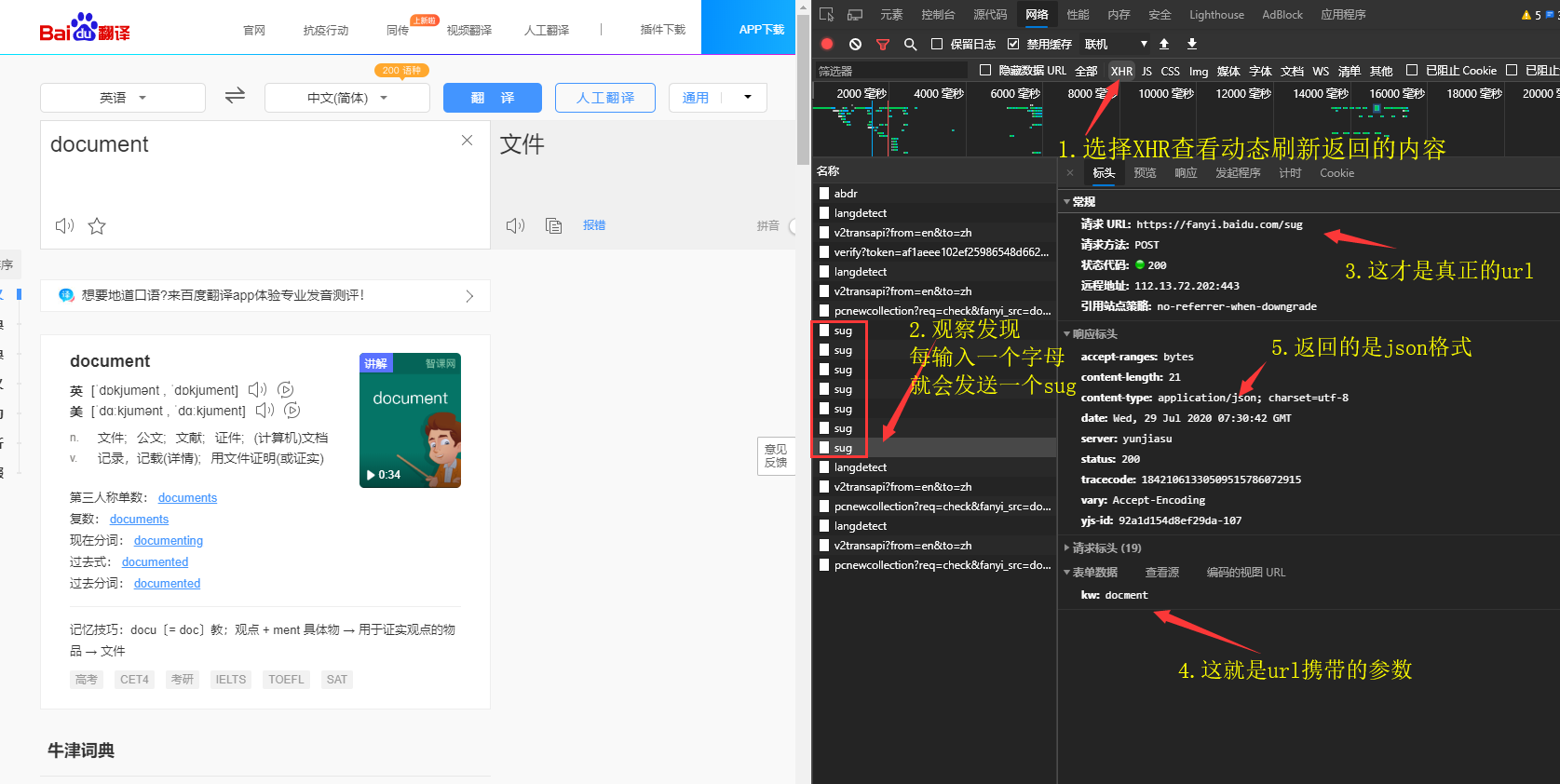
- 可以把筛选器设置到 XHR ,这样可以只查看刷新时返回的数据
- 通过观察可以发现每输入一个字符就会发送一个sug,所以请求url应该是
https://fanyi.baidu.com/sug才对
- 请求方式是
post,携带参数是kw,所以参数部分应该这样写:data = {kw: 'document'}
- 接着看到
Content-Type,返回数据格式是 json,那么就需要用 json 模块来处理。res_json = res.json()
- 最后可以使用
json.dump()将json格式直接写入数据,或者使用json.loads()转换成python对象,再用f.write()写入文件。
| import requests
header = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.44"}
def main():
# 1. 指定url
url = 'https://fanyi.baidu.com/sug'
# 2. 获取查询内容,设置好请求参数
query = input("Enter the word you want to translate: ")
data = {'kw': query}
# 3. 发送请求
res = requests.post(url=url, data=data, headers=header)
# 4. 获取返回内容
res_json = res.json()
# 5. 写入文件
with open('./translation.json', 'w', encoding='utf-8') as f:
json.dump(res_json, fp, ensure_ascii=False)
if __name__ == '__main__':
main()
|