string 实现原理¶
UTF-8¶
在计算机中,一切都是数字「0」和「1」,确切点说应该是「低电平」和「高电平」。
从理论角度来说,「数」是客观存在的,是真理般的存在,而「进制」是主观存在的,是人类掌握「数」的一种工具。
一个数,可以用二进制、八进制、十进制、十六进制、二十六进制、三十八进制等各种进制来表示。不同进制之间可以按照一定规则进行转换,0 和 1 两个数字,可以组成二进制的最基本单位,所以可以通过 101 表示十进制 5,110 表示十进制 6。
于是,在计算机中,不管我们要表示任何数,只要转换成二进制,并替换成计算机中的高低电平,既可以在计算机中确切的表示一个数。
但是人类世界不仅有数,还有文字。文字由一个一个字符组成,正如英文由字母组成,汉字由笔画组成。在计算机中无法直接表示文字,于是计算机先驱们想出了使用“编号约定”的办法,为每一个字符编一个数字编号,这样就使得文字和数字之间有了映射关系,进而可以在计算机中表示文字。
最初的“编号约定”是 ASCII 码表,由于计算机发展于西方,西文的基本单位 26 个字母,大小写一共 52 个,加上一些符号、控制字符,组成了 ASCII 码表。
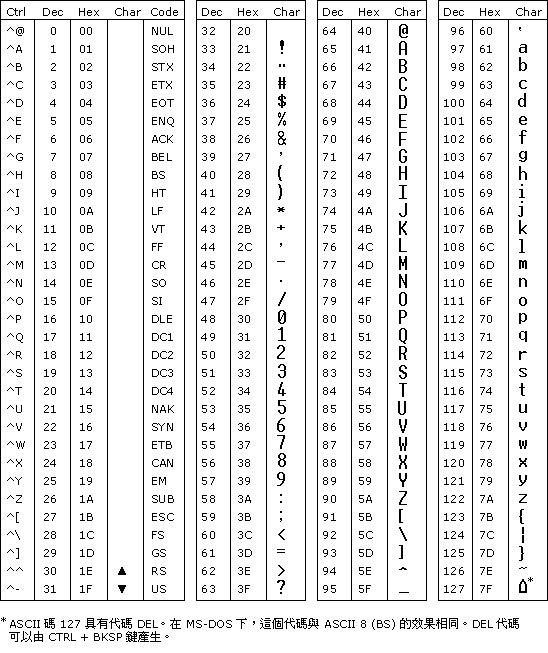
基础 ASCII 码表只有 127 个字符,使用 7 个比特(7 位二进制数)即可表示,而在计算机中 8 个比特组成 1 个字节,所以基础 ASCII 码表也好,扩展 ASCII 码表也好,用 1 个字节足矣。
但是人类语言不止英文一种,还有中文、俄文、日文等等,每种语言一个编码表又使得相互之间会导致码值冲突,混乱不堪。所以 Unicode 通用学术学会便制定了一个通用字符集 UTF,国内也称作“万国码”,由此促进了文字在每一台计算机上的兼容性,防止两台计算机采用不同的编码方式导致 A 计算机的文字到 B 计算机上变成乱码。
UTF 采用的是变长编码(有兴趣的同学自行了解为什么不是定长编码 Golang string ),小编号的字符占少字节,大编号占多字节。每一个字符的编码中的每一个字节都有几个位来用作“前缀”,通过前缀识别出该字节属于哪一个区间。具体如下:
| 编号 | 编码模版 |
|---|---|
| 0~127 | 0xxx xxxx |
| 128~2047 | 110x xxxx 10xx xxxx |
| 2048~65535 | 1110 xxxx 10xx xxxx 10xx xxxx |
例如,英文字符 c 的编号为 99,在 0 到 127 的区间,于是采用 0xxx xxxx 的模板,十进制 99 转为二进制为 1100011,替换到 xxx xxxx,最终编码结果为 0110 0011。
再比如,中文字符 世 的编号为 19990,在 2048 到 65535 的区间,于是采用 1110 xxxx 10xx xxxx 10xx xxxx 的模板,十进制的 19990 转为二进制为 0100 1110 0001 0110 ,替换到模板中,最终编码结果为 1110 0100 1011 1000 1001 0110。
再比如,当计算机看到 1110 0111 10 010101 10 001100 时,第一个字节的前缀 1110 使得计算机明白,这个字符一共占用 3 个字节,除了读取完当前这个字节,还要往后读取 2 个字节。于是从第一个字节中抽取 0111,第二和第三个字节剥离前缀 10 后得到 010101 和 001100,将这三部分拼接得到 0111 010101 001100,十进制为 30028,对应中文字符 界 字。
string 结构¶
说回 string 结构。在 C 语言中,字符串是一个字符数组指针,指向一个字符数组,这样便知道了字符串的开始,使用 \0 表示字符串结束。这样的设计存在的问题是,字符串中无法表示 \0 本身。
golang 在这个基础上进行了改进,没有采用 \0 表示,而是增加了一个 len 字段用于记录字节数组 str 的长度,这样即可以在字符串中使用 \0,而且求字符串长度时直接返回 len 的值即可,时间复杂度仅为 O(1)。
在源码包中 src/runtime/stirng.go:stringStruct 对 字符串 定义如下:
要注意的是,len 表示的是 str 这个 字节数组的长度,不是字符的长度。因为有的字符的长度为 2,有的为 3,有的为 1。
例如一个中英混合的字符串 "abc世界",它的 len 为 9,abc 占用 3 字节,世 占用 3 字节,界 占用 3 字节。
复制问题¶
字符串的复制有 2 种方法:
- 直接赋值
= re-slice语法
采用这两种方法时,两个字符串共享同一个底层字节数组,也就是说,是一种浅复制。
因为 Golang 中字符串一旦定义就不可更改,对字符串中字符的修改较为麻烦,且修改完后会返回一个新的修改好的字节数组,已经不是一开始那个字节数组了,所以可以放心的使用浅复制。
类型转换问题¶
-
一个字符串的值可以显式地转换成一个字节切片
[]byte,反过来也可以。字节byte是uint8的别名,所以[]byte等于[]uint8。 -
一个字符串的值可以显式地转换成一个码点切片
[]rune,反过来也可以。码点rune是uint32的别名,所以[]rune等于[]uint32。 -
所以转换问题的主角就是
string、[]byte、[]rune三者。
[]rune -> string¶
在一个从码点切片 []rune 到字符串 string 的转换中,码点切片中的每个码点值 rune 将被 UTF-8 编码为一到四个字节至结果字符串中。
如果一个码点值是一个不合法的Unicode码点值,则它将被视为「Unicode替换字符值(Unicode replacement character)0xFFFD」。
替换字符值0xFFFD将被 UTF-8 编码为三个字节0xef 0xbf 0xbd。
string -> []rune¶
当一个字符串 string 被转换为一个码点切片 []rune 时,此字符串中存储的字节序列将被解读为一个一个码点的 UTF-8 编码序列。
非法的UTF-8编码字节序列将被转化为Unicode替换字符值0xFFFD。
string -> []byte¶
当一个字符串 string 被转换为一个字节切片 []byte 时,结果切片中的底层字节序列是此字符串中存储的字节序列的一份 深复制。
即Go运行时将为结果切片开辟一块足够大的内存来容纳被复制过来的所有字节。当此字符串的长度较长时,此转换开销是比较大的。
[]byte -> string¶
当一个字节切片 []byte 被转换为一个字符串 string 时,此字节切片中的字节序列也将被 深复制 到结果字符串中。 当此字节切片的长度较长时,此转换开销同样是比较大的。
在这两种转换(string -> []byte、[]byte -> string)中,必须使用深复制的原因是:
Info
[]byte 字节切片中的字节元素是可修改的,但是字符串中的字节是不可修改的;
所以一个 []byte 和一个字符串 string 是不能共享底层字节序列的。
请注意,在字符串和字节切片之间的转换中,
- 非法的UTF-8编码字节序列将被保持原样不变。
- 标准编译器做了一些优化,从而使得这些转换在某些情形下将不用深复制。 这样的情形将在下一节中介绍。
[]byte <-!-> []rune¶
Go并不支持字节切片和码点切片之间的直接转换。我们可以用下面列出的方法来实现这样的转换:
- 利用字符串做为中间过渡。这种方法相对方便但效率较低,因为需要做两次深复制。
- 使用unicode/utf8标准库包中的函数来实现这些转换。 这种方法效率较高,但使用起来不太方便。
- 使用「bytes」标准库包中的 "Runes" 函数 来将一个字节切片转换为码点切片(
[]byte -> []rune:bytes.Runes())。 但此包中没有将码点切片转换为字节切片的函数。
本小节摘自 《Go 101》字符串相关的类型转换
比较问题¶
字符串类型都是可比较类型,因为底层是字节数组,和字符 byte、rune 一样,他们背后的基础类型是 uint8 和 uint32 。
所以两个字符串 string 或 两个字符 byte、rune 之间可以使用等于、不等、大于、大于等于、小于、小于等于的比较:string == string、string != string、string > string、rune >= rune、byte < byte、byte <= byte。
当比较两个字符串值的时候,它们的底层字节将逐一进行比较。
如果一个字符串 a 是另一个字符串 b 的前缀,并且另一个字符串 b 较长; 则另一个字符串 b 为两者中的较大者。
字符串相等比较¶
对于两个字符串相等或不等的比较,Go编译器会先比较他们的 len 字段:
- 如果两个
len的值不相等,则两个字符串肯定不相等; - 如果两个
len的值相等,则比较两个字符串底层的字节数组指针str是否相等,也就是看看是不是引用了同一个底层字节数组。如果是则相等,如果不是则逐个比较每一个字节。