并发安全¶
竞态¶
竞态 是指多个 goroutine 按某些交错顺序执行时,争抢使用同一份临界资源,导致程序无法给出正确的结果。
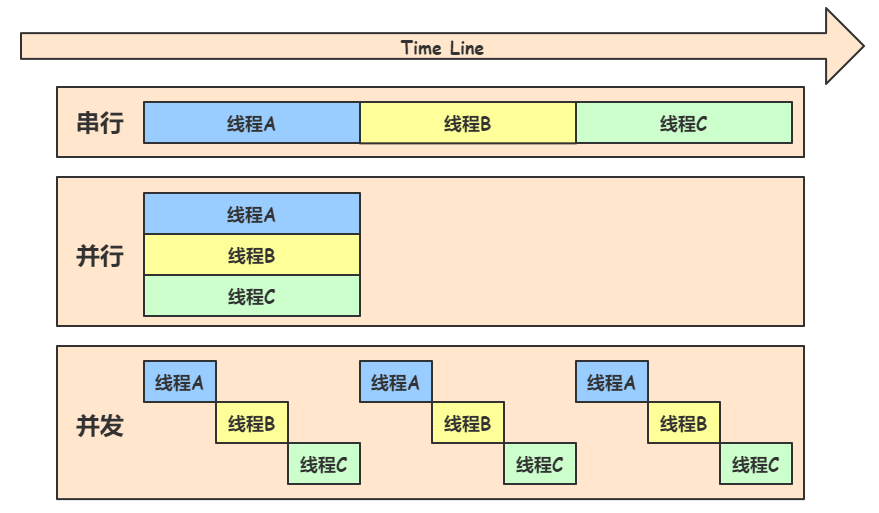
串行程序 中(一个程序只有一个 goroutine),程序中各个步骤的执行顺序由程序逻辑决定,所以单个 goroutine 不会引发竞态问题。
并发程序 中(一个程序有多个 goroutine),每个 goroutine 的执行顺序是不一样的,因此可能会带来竞态问题。
例如:
下面开启新的 goroutine 执行 add()
goroutine 争抢着使用 x 这个临界资源,有可能最终的 x 的结果是正确的,但是main() 提前抢到资源就打印出来了,也有可能两个 子goroutine 争抢时导致 x 被写乱了(发生了竞态)。
避免竞态¶
- 第一种:不要修改变量。这种可以,但不现实,因为实际业务中必然涉及同时读写同一个变量的场景。只能说尽量避免。
- 第二种:上锁
上锁可以很好的解决竞态问题,但是会有些许性能上的损失。
Info
发生竞态的主要原因是因为:多个 goroutine 争抢读写同一个临界资源。这个临界资源可以是打印机、全局变量等等。
举个栗子,
一个人就是一个 goroutine,公共卫生间就是一种临界资源,同一时刻只能有一个人使用(一个临界资源,同一时刻只能有一个 goroutine 读写 )。多个人同时争抢一个公共卫生间肯定出问题。
所以卫生间要加个锁,进去使用的人上锁,使用完了开锁。
使用临界资源的 goroutine 给临界资源上锁,使用完了把锁释放。
Golang 中的 sync 包提供了 Mutex 和 RWMutex 两种锁。
sync.Mutex 互斥锁¶
Mutex 非常简单,只有Lock() 和 Unlock() 两个方法。
Note
加锁
Lock()用于加锁- 加锁规则:
- 如果互斥锁已经被上锁了,则加锁操作阻塞,直到互斥锁被解锁以后才能上锁。
- 如果互斥锁没有被上锁,那么上锁成功。
解锁
Unlock()用于解锁- 解锁规则:释放互斥锁
上锁¶
下面我们对上面的例子中,争抢临界资源的部分上锁。
子goroutine 得到运行的机会,别的 goroutine 都不能访问临界资源,得等到上了锁的 goroutine 释放,别的 goroutine 才能访问。
延迟解锁¶
如果一个 goroutine 上了锁之后忘记释放锁,别的 goroutine 是永远拿不到锁的,还会导致死锁。
在复杂的代码中,很难确定所有分支中的 Lock() 和 Unlock() 成对出现,所以,最好养成 锁成对写、延迟解锁 的习惯。
sync.RWMutex 读写互斥锁¶
读写互斥锁适用于 读多写少 的场景。因为在使用 Mutex 互斥锁的时候,不管是因为要去读上的锁还是要去写上的锁,只要一上了锁,别的 goroutine 就不能上锁,也不能读写。
于是在 读多写少 的场景下,导致少量写操作时,也不能读。所以这种场景要使用 读写互斥锁。
Note
写锁
Lock()函数用于上写锁Unlock()函数用于解写锁- 加锁规则:
- 如果当前的读写锁被上锁了,则 加写锁 操作阻塞直到读写锁被释放
- 如果当前的读写锁没有被锁,则 加写锁 成功
- 释放规则:直接释放
读锁
RLock()函数用于上读锁RUnlock()函数用于解读锁- 加锁规则:
- 如果当前的读写锁 没有被锁,则 加读锁 操作成功
- 如果当前的读写锁 被上了读锁,则 加读锁 操作成功
- 如果当前的读写锁 被上了写锁,则 加读锁 操作阻塞,直到读写锁被释放
Example
Mutex 和 RWMutex 的选择¶
- 仅在绝大部分goroutine都在 获取读锁并且锁竞争比较激烈时(即,goroutine一般都需要等待后才能获到锁),RWMutex才有优势
- 否则,一般使用Mutex即可
Tip
只读场景:sync.map > rwmutex >> mutex 读写场景(边读边写):rwmutex > mutex >> sync.map 读写场景(读80% 写20%):sync.map > rwmutex > mutex 读写场景(读98% 写2%):sync.map > rwmutex >> mutex 只写场景:sync.map >> mutex > rwmutex
sync.Once¶
Once是一个结构体,里面有一把Mutex锁 m,还有一个done标志位用来标记f是否执行过了。(0未执行,1已执行)Once只有一个Do()方法,其中检查了一下标志位,如果为 0 表示f未执行过,调用doSlow();非 0 表示执行过了,直接返回doSlow()中,先是上锁,然后检查done标志位,看看f是否执行过,如果没有执行,就执行,然后标志位置为 1。
用 sync.Once 写一个单例模式:
sync.Map¶
Info
Golang 中内置的 map 不是并发安全的,在对 map 并发写的时候会出现问题。
Golang 的 sync 包中提供了一个开箱即用的并发安全版map:sync.Map。
开箱即用,即表示不需要 make() 函数初始化就能直接使用,同时内置了诸如 Store、Load、Delete、Range 等操作。
先看对内置 map 并发写会发生什么。
``` fatal error: k=:0,v:=0 concurrent map writes k=:19,v:=19 fatal error: concurrent map writes ...
采用 并发安全版:
原子操作¶
代码中的加锁操作因为涉及内核态的上下文切换会比较耗时、代价比较高。
针对基本数据类型我们还可以使用原子操作来保证并发安全,因为原子操作是 Go 语言提供的方法它在用户态就可以完成,
因此性能比加锁操作更好。Go语言中原子操作由内置的标准库 sync/atomic 提供。
atomic 包¶
| 读取操作 |
|---|
| func LoadInt32(addr *int32) (val int32) |
| func LoadInt64(addr *int64) (val int64) |
| func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer) |
| func LoadUint32(addr *uint32) (val uint32) |
| func LoadUint64(addr *uint64) (val uint64) |
| func LoadUintptr(addr *uintptr) (val uintptr) |
| 写入操作 |
|---|
| func StoreInt32(addr *int32, val int32) |
| func StoreInt64(addr *int64, val int64) |
| func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer) |
| func StoreUint32(addr *uint32, val uint32) |
| func StoreUint64(addr *uint64, val uint64) |
| func StoreUintptr(addr *uintptr, val uintptr) |
| 修改操作 |
|---|
| func AddInt32(addr *int32, delta int32) (new int32) |
| func AddInt64(addr *int64, delta int64) (new int64) |
| func AddUint32(addr *uint32, delta uint32) (new uint32) |
| func AddUint64(addr *uint64, delta uint64) (new uint64) |
| func AddUintptr(addr *uintptr, delta uintptr) (new uintptr) |
| 交换操作 |
|---|
| func SwapInt32(addr *int32, new int32) (old int32) |
| func SwapInt64(addr *int64, new int64) (old int64) |
| func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer) |
| func SwapUint32(addr *uint32, new uint32) (old uint32) |
| func SwapUint64(addr *uint64, new uint64) (old uint64) |
| func SwapUintptr(addr *uintptr, new uintptr) (old uintptr) |
| 比较并交换操作 |
|---|
| func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) |
| func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool) |
| func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool) |
| func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool) |
| func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool) |
| func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool) |
从结果可以看出,非并发安全版连结果都不对,加锁版安全,原子版安全且效率更高。
atomic 包提供了底层的原子级内存操作,对于同步算法的实现很有用。这些函数必须谨慎地保证正确使用。除了某些特殊的底层应用,使用通道或者sync包的函数/类型实现同步更好。