进程
进程,是资源分配的单位
程序:例如xxx.py这是程序,是静态的
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。
进程,是资源分配的单位
线程,是操作系统调度的单位
进程的状态
工作中,任务数往往大于CPU核心数,即一定有一些任何正在执行,而另外一些任务在等待CPU进行执行
因此进程有不同的状态
进程的状态分为:新建、就绪、运行、等待(堵塞)、死亡
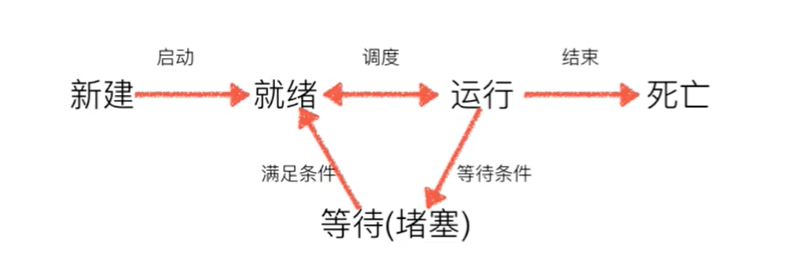
- 就绪态:运行的条件都已经具备,正在等在CPU执行
- 执行态:CPU正在执行其功能
- 等待态:等待某些条件满足;例如一个程序sleep了,就处于等待态
进程就好像流水线。
一个进程就是一条流水线,每条流水线之间是相互独立的;
流水线履带上的产品就是全局变量;
流水线上的工人就是线程;
产品(全局变量)对于同一条流水线的工人(线程)来说是共享的,每个人都可以访问
流水线(进程)之间是相互独立的,不能流水线A的产品可以被流水线B访问,那不就乱套了。
创建进程
创建进程分为三步:
- 导入 multiprocessing 模块
- 创建一个 Process 对象
- 通过 Process 对象启动线程
创建一个 Process对象的时候可以传入参数
multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
- 应始终使用关键字参数调用构造函数。
- group:应该始终是 None ;它仅用于兼容 threading.Thread 。
- target:是由 run() 方法调用的可调用对象。它默认为 None ,意味着什么都没有被调用。
- name:是进程名称
- args:是目标调用的参数元组。
- kwargs:是目标调用的关键字参数字典。
- daemon:
- 如果提供,则键参数 daemon 将进程 daemon 标志设置为 True 或 False 。
- 如果是 None (默认值),则该标志将从创建的进程继承。
- 如果子类重载了构造函数,必须先调用父类构造器
Process.__init__(),再做其他事情。
| import multiprocessing
import time
def say_hi():
while True:
print("Hi-------")
time.sleep(1)
def say_yes():
while True:
print("Yes------")
time.sleep(1)
def main():
p1 = multiprocessing.Process(target=say_hi)
p2 = multiprocessing.Process(target=say_yes)
p1.start()
p2.start()
if __name__ == '__main__':
main()
--------------------------------------------------
# Output:
Hi-------
Yes------
Hi-------
Yes------
Hi-------
Yes------
Hi-------
...
|
进程间通信
进程间的通信有很多中方式,比如通过带网络功能的socket,或者队列Queue
假设两个进程之间要通信,进程A向内存中的Queue放要通信的内容,进程B去Queue中取即可。
进程是运行在内存中的,Queue也是运行在内存中的,所以速度很快。
Queue对于进程来说是共享的。
| import multiprocessing as p
def download_from_web(q):
"""下载数据"""
# 模拟从网上下载的数据
data = [11, 22, 33, 44]
# 向队列中写入数据
for temp in data:
if not q.full(): # 如果队列未满
q.put(temp) # 通过 put 将内容放进队列
print("download: 下载完成并存入队列")
def analysis_data(q):
"""数据处理"""
# 从队列中获取数据
data = list()
# 模拟数据处理
while True:
data.append(q.get()) # 通过 get 取队列中的内容
if q.empty(): # 如果队列为空则退出
break
print("analysis:", data)
def main():
# 1.创建一个队列
q = p.Queue(3)
# 2.创建多个进程,将队列的应用当作实参传递到里面
p1 = p.Process(target=download_from_web, args=(q, ))
p2 = p.Process(target=analysis_data, args=(q, ))
p1.start()
p2.start()
if __name__ == "__main__":
main()
def download_from_web(q):
"""下载数据"""
# 模拟从网上下载的数据
data = [11, 22, 33, 44]
# 向队列中写入数据
for temp in data:
q.put(temp)
print("download: 下载完成并存入队列")
def analysis_data(q):
"""数据处理"""
# 从队列中获取数据
data = list()
# 模拟数据处理
while True:
data.append(q.get())
if q.empty():
break
print("analysis:", data)
def main():
# 1.创建一个队列
q = p.Queue(3)
# 2.创建多个进程,将队列的应用当作实参传递到里面
p1 = p.Process(target=download_from_web, args=(q, ))
p2 = p.Process(target=analysis_data, args=(q, ))
p1.start()
p2.start()
if __name__ == "__main__":
main()
--------------------------------------------------
# Output:
download: 下载完成并存入队列
analysis: [11, 22, 33, 44]
|
q.put(obj[, block[, timeout])- obj:要传递的内容
- block:阻塞,默认True
- True,队列满了以后会一直等待
- Flase,队列满了之后会抛出
queue.Full错误
- timeout:浮点型,单位——秒,默认None;
- 值为正数时,等待时长为设定的秒数
- 值为-1时,将无限等待
- blocking=Flase时,timeout不起作用。
-
如果队列关闭已经关闭会抛出ValueError(3.8+)
q.put_nowait(obj)相当于q.put(block=Flase)
-
q.get([block[, timeout])
- block:阻塞,默认True
- True,队列空了以后会一直等待
- Flase,队列空了之后会抛出
queue.Empty错误
- timeout:浮点型,单位——秒,默认None;
- 值为正数时,等待时长为设定的秒数
- 值为-1时,将无限等待
- blocking=Flase时,timeout不起作用。
- 如果队列关闭已经关闭会抛出
ValueError(3.8+)
q.get_nowait()相当于q.get(block=Flase)
进程池
进程的创建和消费是很耗费资源的,而实际情况中可能出现成千上百万个进程需要执行,这时候不可能每个进程都单独创建和销毁
这些进程大同小异,但是进程的创建和销毁是相同的。
于是我们可以把创建和销毁的工作抽取出来,通过更换进程的内容,以此达到较小开销的目的。
这种技术叫做 进程池
进程池就好比公园里的湖,进程就好比船。
你作为老板,今天来了一个人要划船,你去买一艘船,客人划完了你把船卖了。
明天再来两个客人,你又去买两艘船,客人划完了你又把船卖了。
万一来了一万个客人,你...没钱买船了哈哈哈。
这是普通的进程使用方法。
你作为老板,先买好N艘船(开启进程池),来了一个客人,上船,用完了换你,下一个客人上去...
等到哪天生意不做了关门,就把船一起卖掉关门(关闭进程池)。
这是进程池的使用方法 。省下了买船卖船(创建和销毁进程)的功夫。
进程池中最大容量能同时容纳多少个进程是由开发者指定的,具体多少个要经过测试人员压力测试以后得出一个合适的数量。
当进程池创建以后,不会立即工作,而是等到有进程被创建了才开始工作。
| from multiprocessing import Pool
import os
import time
import random
def work(msg):
print("Process-{} running, pid:{}".format(msg, os.getpid()))
start = time.time()
time.sleep(random.random() * 2)
end = time.time()
print("Process-{} finish, time consuming:{:.2f}".format(msg, end - start))
def main():
po = Pool(3) # 定义一个进程池,最大进程数为3
for i in range(1, 11):
# Pool.apply_async(要调用的目标, (传递给目标的参数元组,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(work, (i, ))
print("------start------")
po.close() # 关闭进程池,关闭后po不在接收新的请求
po.join() # 等待po中所有子进程执行完后再关闭,必须放在close语句后
print("-------end-------")
if __name__ == '__main__':
main()
--------------------------------------------------
# Output:
------start------
Process-1 running, pid:20364
Process-2 running, pid:15912
Process-3 running, pid:16504
Process-2 finish, time consuming:1.01
Process-4 running, pid:15912
Process-3 finish, time consuming:1.03
Process-5 running, pid:16504
Process-4 finish, time consuming:0.17
Process-6 running, pid:15912
Process-5 finish, time consuming:0.23
Process-7 running, pid:16504
Process-1 finish, time consuming:1.50
Process-8 running, pid:20364
Process-6 finish, time consuming:1.43
Process-9 running, pid:15912
Process-8 finish, time consuming:1.65
Process-10 running, pid:20364
Process-9 finish, time consuming:0.55
Process-7 finish, time consuming:1.99
Process-10 finish, time consuming:0.20
-------end-------
|
创建进程池
创建进程池总共分步:
- 导入 multiprocessing 模块
- 创建一个 Pool 对象并指定最大进程数
- 使用
apply()或apply_async()方法
- 使用
close()方法停止接收进程
- 使用
join()方法声明等待子进程完毕再关闭进程池