SQL 执行过程¶
Quote
参考自 小林 Coding 执行一条 select 语句,期间发生了什么?
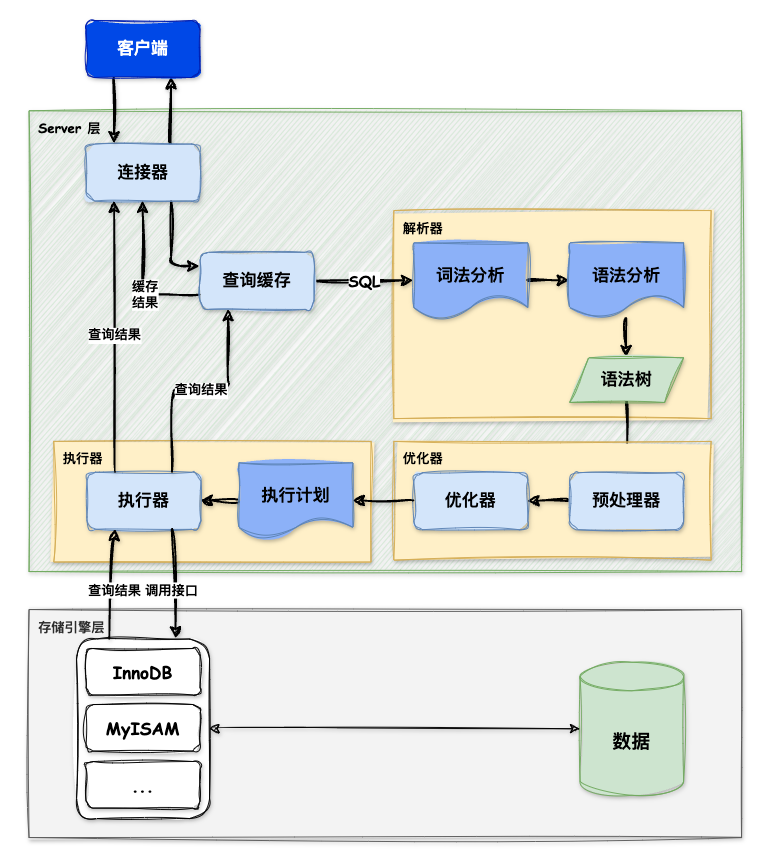
MySQL 的架构分为:Server层 和 存储引擎层
-
Server 层:负责建立链接、分析、执行 SQL。 大部分核心功能模块都在 Server 层,主要包括连接器、查询缓存、解析器、预处理器、优化器、执行器等。
另外所有内置函数(如日期、时间、数学和加密函数等)和所有跨存储引擎的功能(如存储过程、触发器、视图等)都在 Server 层。
-
存储引擎层:负责数据的存储和提取。支持 InnoDB、MyISAM、Memory 等多个存储引擎,不同的存储引擎共用一个 Server 层。 常说的索引数据结构,就是存储引擎层实现的,不同的存储引擎支持的索引类型和数据结构不同。
1. 连接器¶
Tip
连接器用于管理连接、权限验证。
不论是 MySQL 客户端,还是 JDBC 等连接驱动,都是通过连接器分配的一个句柄来进行交互。
连接操作¶
- MySQL 是基于 TCP 协议 进行传输的。
- 完成 TCP 连接建立后,连接器会验证用户名和密码,若验证通过则会读取该用户的权限列表,直到断开连接之前,都使用连接时读取到的权限进行判断,所以如果管理员中途修改该用户的权限并不影响已经存在的连接,只有重新连接才会使用新的权限设置。
> show processlist;命令可以查看当前 MySQL服务被多少客户端连接,以及连接的情况。> kill connection +id;命令可以手动断开空闲连接。如断开 ID 为 6 的连接:kill connection +6;。 被断开的连接不会马上知道,而是等到下一次请求查询的时候才会收到ERROR 2013(HY000)的报错。wait_timeout参数用于控制空闲连接可以持有连接多久,超过该参数设置的值会被断开。
长短连接¶
MySQL 也有长短连接的区别。
Tip
短连接会增加连接的开销,导致程序响应慢。长连接则减少了建立连接的开销,但是可能会导致占用内存增多。
因为 MySQL 在执行查询的过程中,使用内存管理连接对象,这些对象资源只有在连接断开时才会释放。如果长连接太多,会导致 MySQL 服务内存占用过高,被系统强制kill,导致 MySQL 服务异常重启。
解决办法有两种: 1. 定期断开长连接:定期把长连接断开(跟空闲不一样哦) 2. 客户端主动重置连接:当客户端执行了一个很大的操作后,在 代码中主动调用 mysql_reset_connection() 函数 或者 关闭后重新连接(使用连接池的情况下) 来重置连接。 这个过程不需要重新连接和重新校验权限,但是会把连接恢复到刚刚创建连接时的状态。
2. 查询缓存¶
如果 SQL 是 SELECT 查询,MySQL 会先去查询缓存里查找结果。key 为 SQL 语句,value 为查询结果。
但其实查询缓存很鸡肋,因为经常缓存未命中。所以 MySQL8.0 在 Server 层将查询缓存删掉了。
3. 解析 SQL¶
解析器做两件事情:词法分析 和 语法分析。
词法分析器 会根据输入的 SQL(其实就是一串字符串)识别出关键字和非关键字。
例如 SELECT username, ismale FROM userinfo WHERE id = 1 这条 SQL 会得到 SELECT、FROM、WHERE、= 这 4 个关键字 Token,
还有 username、ismale、userinfo、id、1 这个 5 个非关键字 Token。
语法分析器 则根据词法分析的结果(其实就是一个字符串数组),还有语法规则,去构建出 SQL 的语法树。 如果有语法错误则会抛出,没有则输出一颗多叉树,即语法树。

4. 执行 SQL¶
Tip
每条 SELECT 查询语句可以分为三个阶段:
- prepare 阶段,即预处理阶段
- optimize 阶段,即优化阶段
- execute 阶段,即执行阶段
预处理器¶
预处理器主要做这些事情:
- 检查要查询的表和字段是否存在
- 将 SELECT * 中的 * 符号扩展为表上所有的列
优化器¶
经过预处理阶段后,还需要为 SQL 查询语句指定一个执行计划。这个工作由「优化器」来完成。
优化器主要负责将 SQL 查询语句的执行方案确定下来。比如在表中有多个索引时,优化器会基于查询成本考虑,选择成本最小的索引。实在没有所以可用,则会全表扫描。
使用 EXPLAIN 加上查询语句来查看执行计划。
执行器¶
确定执行计划以后,接下来就是真正开始执行 SQL 语句了,这个工作由「执行器」完成。
执行过程中,执行器和存储引擎交互,交互是以记录为单位的。
以下是三种执行过程的示例
主键索引查询¶
这条语句使用到了主键索引,而且是等值查询。由于主键是唯一的,所以优化器决定使用访问类型为 const 进行查询。执行流程如下:
- 执行器第一次查询,会调用 read_first_record 函数指针指向的函数,因为查询类型为 const,所以指针会指向 InnDB 的索引查询接口,把 id = 1 传进去,让引擎定位符合条件的第一条记录。