事务¶
Quote
参考自 小林 Coding 事务隔离级别是怎么实现的?
在 MySQL 中,可以通过 BEGIN 或 START TRANSACTION 或 START TRANSACTION WITH CONSISTENT SNAPSHOT 开启事务,通过 COMMIT 提交事务,通过 ROLLBACK 回滚事务。
如果只是执行一条「增删改」的 SQL 语句,那么 MySQL 会自动 隐式开启事务 来执行,执行完就自动提交事务。
Example
事务的特性¶
事务(Transaction),由一组操作构成的可靠的独立的工作单元。具备 ACID 特性,即 原子性,一致性,隔离性,持久性。
-
原子性 Atomicity
事务中的所有操作 要么全部成功,要么全部失败。只要有一项失败,整个事务的所有操作全部回滚。
-
一致性 Consistency
事务的执行不能破坏数据库的完整性和一致性,事务在执行之前和之后,数据库都必须处于一致性状态。
-
隔离性 Isolation
(读未提交,读已提交,可重复读,可串行化)在并发环境中,并发的事务是相互隔离的,一个事务的执行不能被其他事务干扰。即 不同的事务并发操作相同的数据时,并发执行的各个事务之间不能相互干扰。
-
持久性 Durability
一个事务一旦提交,它对数据库中对应数据的状态变更就应该是永久性的,要求遇到机器宕机、系统崩溃等意外发生后,依然能恢复到事务成功结束时的状态。
InnoDB 通过 日志和锁 来保证事务的 ACID 特性,具体如下:
- 通过 Redo Log 来保障事务的 持久性
- 通过 Undo Log 来保障事务的 原子性
- 通过 MVCC机制或锁 来保证事务的 隔离性
- 通过 持久性+原子性+隔离性 来保证 一致性
并行事务会引发的问题¶
-
脏读 Dirty Read: 事务 A 读到了事务 B 还未提交的数据。
-
不可重复读 Non-Repeatable Read: 事务 A 读取某些数据后,再次读取该数据发现与上次不同,因为事务 B 对其进行了变更或删除。
-
幻读 Phantom Read: 事务 A 在读某个范围,事务 B 新增或删除了满足该范围的记录,当 A 再次进行查询的时候发现多了或少了。
如果一个事务「读到」了另一个事务「还未提交的修改后的数据」,就意味着 脏读。

事务 A 还没提交意味着有可能触发回滚,那么事务 B 读到的数据并不能保证是最终的数据,这就是脏读。
在一个事务内「多次读取同一个数据」,如果每次读取的「数据不一样」,就说明出现了 不可重复读。
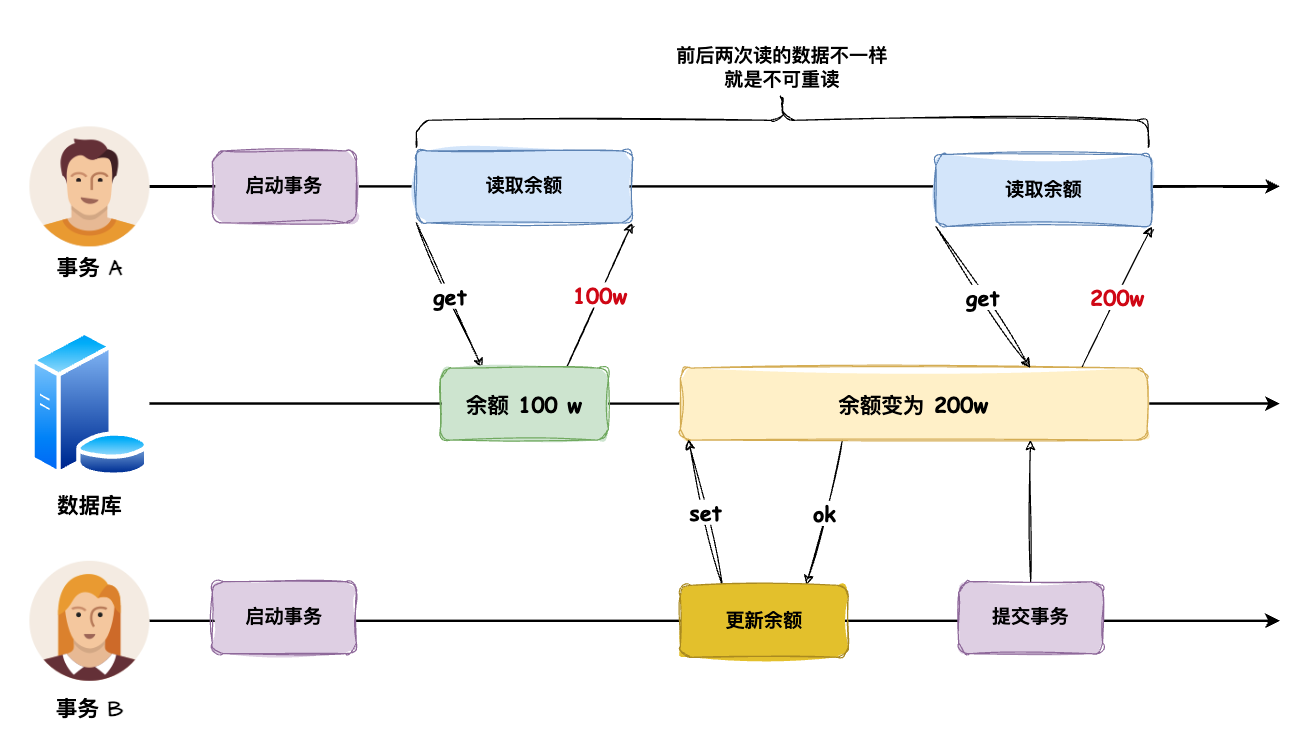
事务 A 在读取数据的过程中,事务 B 修改了数据,导致事务 A 两次读取的数据不一样,这就是不可重复读。
在一个事务内「多次读取同一个范围的数据」,如果每次读取的「数量不一样」,就说明出现了 幻读。
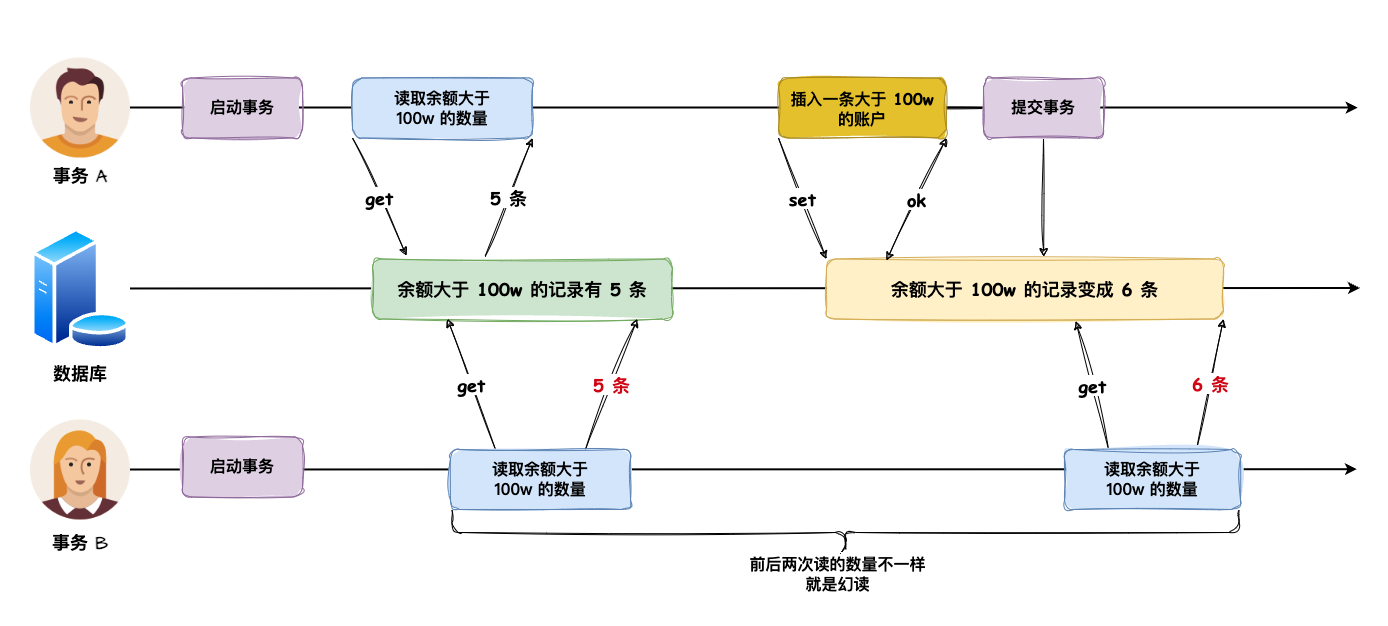
事务 A 在读取数据的过程中,事务 B 新增了数据,导致事务 A 两次读取的数据量不一样,这就是幻读。
脏读、不可重复读 和 幻读 的区别在于:
- 幻读 是在同一事务中,相同条件下,两次查询出来的 记录数 不一样,强调的是 数量、增删操作;
- 不可重复读 是在同一事务中,相同条件下,两次查询出来的 数据 不一样,强调的是 数据、修改操作;
- 脏读 是读到了未提交的数据。
事务隔离级别¶
Note
对于上述问题,SQL 标准提出了四种隔离级别来规避这些问题,分别是: 读未提交、读已提交、可重复读、串行化。
- 读未提交 Read Uncommitted: 指一个事务 A 还没提交时,它做的变更 就已经能 被其他事务读到。这会导致 脏读、不可重复读 和 幻读。
- 读已提交 Read Committed: 指一个事务 A 提交以后,它做的变更 才能 被其他事务读到。这会导致 不可重复读 和 幻读。
- 可重复读 Repeatable Read: 指一个事务 B 执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的。只有自己这个事务 B 提交以后,才能 看到最新的数据。这会导致 幻读。
- 串行化 Serializable: 对记录加上读写锁,当多个事务对这条记录进行读写操作时,如果发生读写冲突,后访问的事务必须等前一个事务执行完成才能继续。这是性能最差的隔离级别,但是可以彻底避免 幻读。
-
按隔离水平高低排序如下: 串行化 > 可重复读 > 读已提交 > 读未提交
-
不同的隔离级别会导致不同的问题,如下表所示:
| 读未提交 | 读已提交 | 可重复读 | 串行化 |
|---|---|---|---|
| 脏读 | 脏读 | 脏读 | 脏读 |
| 不可重复读 | 不可重复读 | 不可重复读 | 不可重复读 |
| 幻读 | 幻读 | 幻读 | 幻读 |
MySQL 支持这 4 种隔离级别,可以通过 SET TRANSACTION ISOLATION LEVEL 来设置。但和 SQL 标准不同的是,MySQL 的默认隔离级别是 可重复读,而不是 读已提交。
并且在 MySQL 中,可重复读 是通过 MVCC 机制来实现的。可以很大程度上(不是彻底)避免 幻读 问题。
MySQL 可重复读解决方案¶
具体的方案有两种:
-
针对 快照读 ,是通过 MVCC 解决幻读问题;因为 可重复读 隔离级别下,事务执行时会创建一个 ReadView,用于保存事务启动时的快照。 这样在事务执行过程中,其他事务对数据的修改不会影响到当前事务的读取。就算事务执行期间数据被修改也不影响。
-
针对 当前读 ,是通过 Next-Key Lock 解决幻读问题;因为在执行
SELECT ... FOR UPDATE语句时,会对查询的数据加上 Next-Key Lock, 其他事务如果在 Next-Key Lock 锁住的范围内插入删除数据,就会被阻塞,直到当前事务执行完成,这样就避免了幻读问题。
示例
| 事务 A | 事务 B |
|---|---|
| 启动事务 A | 启动事务 B |
| 查询余额 v0 100w | |
| 查询得到余额 100w | |
| 修改余额为 200w | |
| 查询余额 v1 | |
| 提交事务 B | |
| 查询余额 v2 | |
| 提交事务 A | |
| 查询余额 v3 |
假设有一张账户余额表,里面有一条记录余额为 100w 的记录,然后有两个并发事务,事务 A 仅负责查询余额,事务 B 会将余额改成 200w。
| 事务 A | 事务 B |
|---|---|
| 启动事务 A | 启动事务 B |
| 查询余额 v0 100w | |
| 查询得到余额 100w | |
| 修改余额为 200w | |
| 查询余额 v1 200w | |
| 提交事务 B | |
| 查询余额 v2 200w | |
| 提交事务 A | |
| 查询余额 v3 200w |
在「读未提交」隔离级别下,事务 B 修改了余额,事务 A 在查询余额 v1 时就会直接读到 200w,这就是脏读。 v2、v3 自然也是读到 200w。
| 事务 A | 事务 B |
|---|---|
| 启动事务 A | 启动事务 B |
| 查询余额 v0 100w | |
| 查询得到余额 100w | |
| 修改余额为 200w | |
| 查询余额 v1 100w | |
| 提交事务 B | |
| 查询余额 v2 200w | |
| 提交事务 A | |
| 查询余额 v3 200w |
在「读已提交」隔离级别下,事务 B 修改了余额,事务 A 在查询余额 v1 时还是读到 100w,因为事务 B 还未提交。 当事务 B 提交以后,事务 A 在查询余额 v2 时读到 200w,v3 也是 200w。
| 事务 A | 事务 B |
|---|---|
| 启动事务 A | 启动事务 B |
| 查询余额 v0 100w | |
| 查询得到余额 100w | |
| 修改余额为 200w | |
| 查询余额 v1 100w | |
| 提交事务 B | |
| 查询余额 v2 100w | |
| 提交事务 A | |
| 查询余额 v3 200w |
在「可重复读」隔离级别下,事务 B 修改了余额,事务 A 在查询余额 v1 时读到 100w,v2 也是 100w,因为此时事务 A 还没有提交,它的快照是 100w。 当事务 A 提交以后,事务 A 在查询余额 v3 时读到就是 200w。
| 事务 A | 事务 B |
|---|---|
| 启动事务 A | 启动事务 B |
| 查询余额 v0 100w | |
| 查询得到余额 100w | |
| 修改余额为 200w | |
| 查询余额 v1 100w | |
| 提交事务 B | |
| 查询余额 v2 100w | |
| 提交事务 A | |
| 查询余额 v3 100w |
在「串行化」隔离级别下,事务 B 修改余额时会被阻塞,因为事务 A 在一开始查询v0时就对余额加了锁,直到事务 A 提交后,事务 B 才能继续执行。 所以事务 A 在查询余额 v1、v2、v3 时都是 100w。
四种隔离级别的实现¶
- 对于「读未提交」级别来说,因为可以读到未提交的数据,所以直接读最新数据就行。
- 对于「串行化」级别来说,通过加读写锁的方式直接避免并行访问。
- 对于「读已提交」和「可重复读」级别来说,需要通过 ReadView 来实现。ReadView 就是对数据打了一个快照。 「读已提交」级别是在「每个语句执行前」都重新生成一个 ReadView, 而「可重复读」级别是在「事务启动时」生成一个 ReadView,然后整个事务期间都用这个 ReadView 读取到的数据。
注意,开始执行事务,并不意味着启动了事务。MySQL 有两种开启事务的方式:
begin或start transaction命令,这种方式只有在执行到第一条查询语句时才会启动事务,这时候才会生成 ReadView。start transaction with consistent snapshot命令,这种方式在执行到这条命令时就会启动事务,生成 ReadView。
ReadView、版本链、MVCC¶
ReadView¶
ReadView 是 InnoDB 用来实现 MVCC 的重要数据结构,用于在不同的事务隔离级别下,提供不同的读取数据的方式。
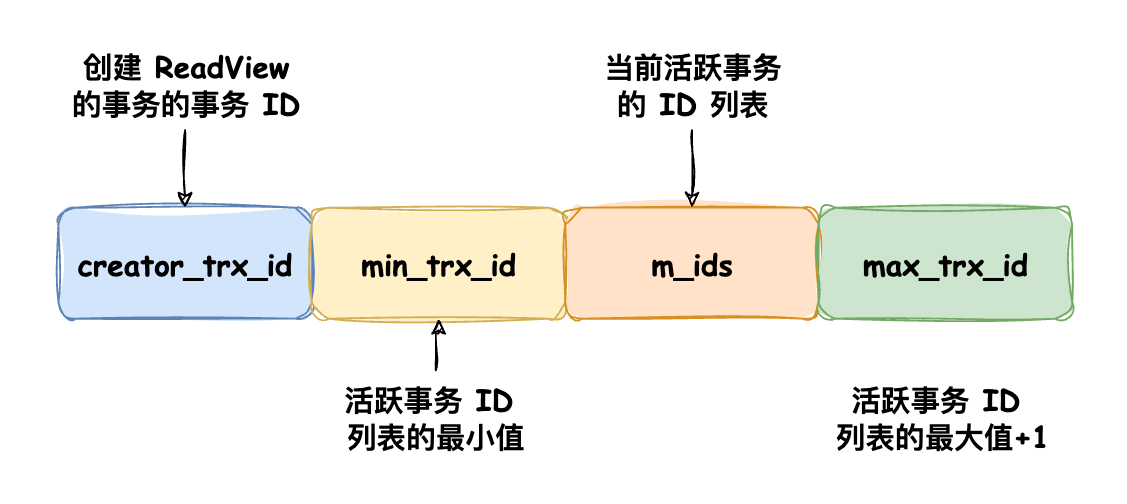
ReadView 中有 4 个重要字段:
- m_ids: 指在创建 ReadView 时,当前和数据库中 「活跃事务」的事务 ID 列表。“活跃事务”指的就是启动了但还没提交的事务。
- min_trx_id: 指在创建 ReadView 时,当前和数据库中 「活跃事务」的最小事务 ID,也就是 m_ids 中的最小值。
- max_trx_id: 指在创建 ReadView 时间点的最大事务 ID,但是这个值并不是 m_ids 中的最大值,而是 m_ids 中的最大值 + 1。
- creator_trx_id: 指 创建该 ReadView 的事务 ID。
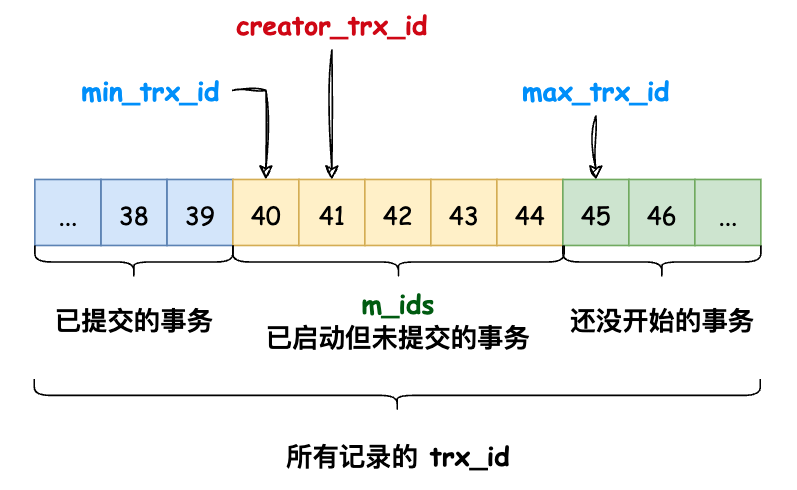
有了 「ReadView」 以后只是有了一个视图,还需要搭配 「版本链」,根据 「隔离级别」 来实现 MVCC。
版本链¶
在 存储结构 中提到,数据表中的每一行为单位,行中除了真实数据、变长字段长度列表、NULL bitmap、头信息外,还有两个隐藏字段:trx_id 和 roll_pointer。
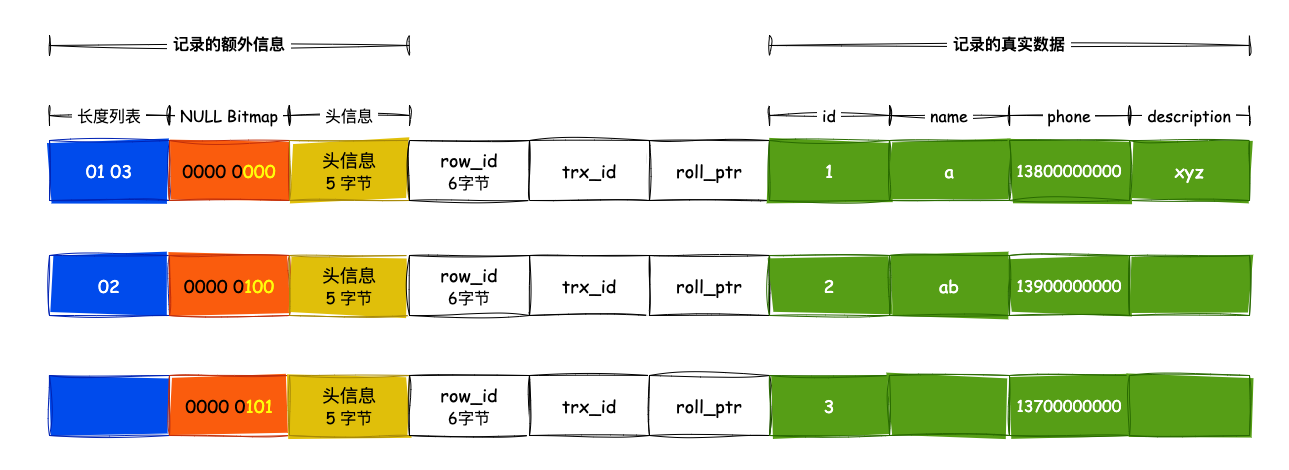
trx_id 表明的是这一行数据是被哪个事务修改的,这是一个填写了以后就不变的值。如果修改数据,会再复制一行,然后填上新的事务 ID,并将 roll_pointer 指向这条旧的行。 由此,版本链就形成了。
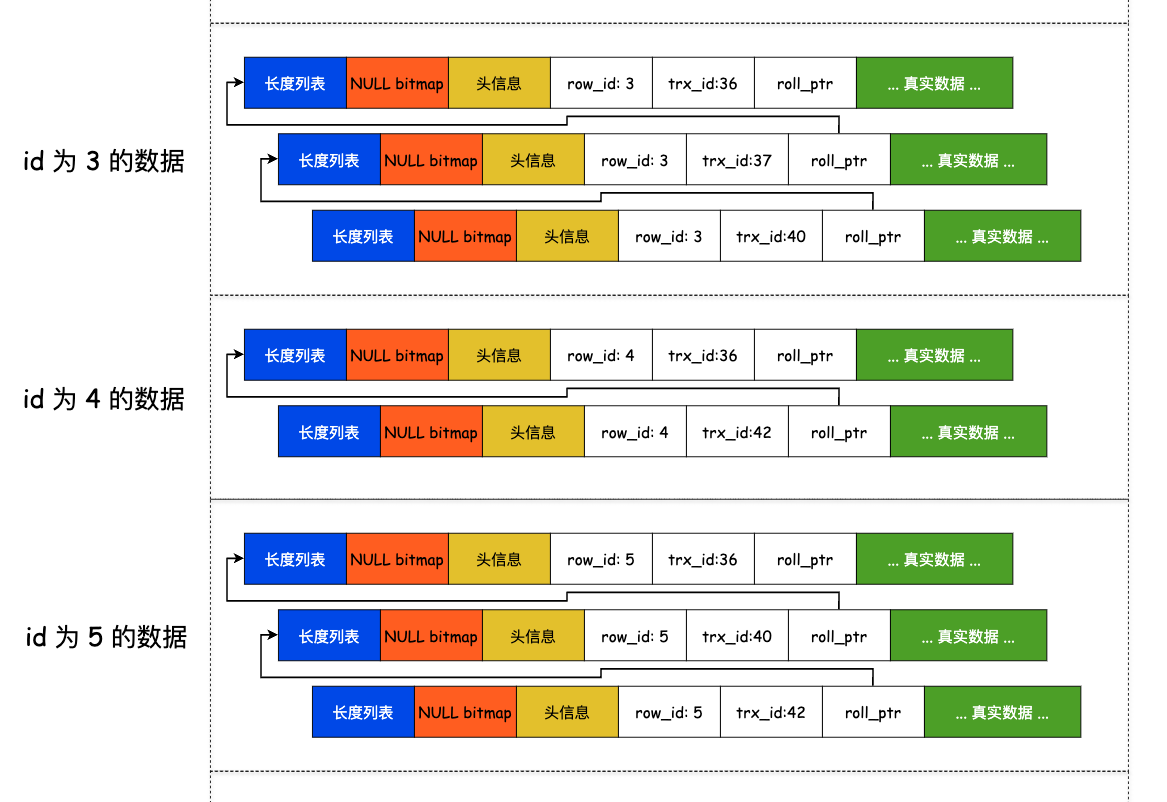
所以 trx_id 可以看做是记录的版本号。
MVCC (Multi-Version Concurrency Control)¶
现在我们可以通过 ReadView 和版本链连实现 MVCC 了。
一个事务去访问记录的时候,除了自己更新的记录总是可见之外,还有一下几种情况:
- 记录的 trx_id < min_trx_id,意味着当前读到记录是 ReadView 创建前提交的事务写的,可以放心读,也就是该版本的记录对当前事务 可见。
- 记录的 trx_id = creator_trx_id,意味着当前读到记录是当前事务写的,也可以放心读,也就是该版本的记录对当前事务 可见。
- 记录的 trx_id > max_trx_id,意味着当前读到记录是在 ReadView 创建后其他事务写的,那么这条记录对当前事务 不可见,那么拿着 roll_pointer 找到上一版本的记录,继续第一步。
- 记录的 trx_id 在 min_trx_id 到 max_trx_id 之间,需要查看 trx_id 是否在 m_ids 中:
- 如果 存在,说明写这条记录的事务还未提交,那么:
- 如果是「读未提交」隔离级别,那么可以读,该版本的记录对当前事务 可见;
- 如果是「读未提交」、「可重复读」、「串行化」,则该版本的记录对当前事务 不可见,那么拿着 roll_pointer 找到上一版本的记录,继续第一步。
- 如果 不存在,说明写这条记录的事务已经提交,那么这条记录对当前事务 可见。
- 如果 存在,说明写这条记录的事务还未提交,那么:
通过 「ReadView」 配合 「版本链」 以及 「隔离级别」,来控制多个事务并发访问同一个记录时如何读写,这就是 「MVCC」。
具体例子推荐 Read View 在 MVCC 里如何工作的?